This blog entry is a follow-up answer I got after my tutorial session on ATDD/BDD at the recent SoCraTes conference in Soltau, Germany (YAY! We’re back to conferring in person!) After showing the participants how I struggle with a new (to me) ATDD/BDD testing framework, raw and unscripted, alongside answering questions raised by the attending participants, one person approached me with a question that I could not answer on the spot directly since I needed a break. Although I offered to get back to me later during the conference days, we never got to chat again. Maybe this might be of some help to others.
All that said, the question raised as I recall understanding it was something like this:
How would you test an application on the user interface? We have this old application, pretty old, and we just seem able to hook examples exemplifying business rules by going through the GUI.
My elobarate answer(s) and perspective(s) are the following.
First things first: Avoid automating your tests through the GUI whenever you can
Without going into too much detail, user interface components and the main application on modern systems usually run in separate threads in the operating system you are using in order to not block execution between the two. That holds for rich clients and desktop applications in the same way as the web frontend of your website or your mobile phone frontend to some service somewhere. Usually, these two – for the sake of simplicity let’s assume we have two though there might be more – separate threads have measures to call a function on the other thread in order to carry out the task at hand. In order to stay responsive, these exchanges mostly happen with asynchronous interactions between the two threads.
So, when running an automated test against the GUI, triggering GUI components to carry out the actions as if a user clicked on the GUI, you end up with maybe three different things running in separate threads: your automated test runner, the GUI component, and the main component where the magic might happen. Since your test probably carries out some button click or text input into a text field then calling some other components to store the text in the database or something, you probably want to check that the resulting operation did the right thing and persisted the data your automated test put in.
In order to check for the right results or wait for an operation to complete, your test would need to actively wait for the end of the operation that you triggered. Since all this stuff runs asychronously, you need to put in active waiting cycles into your automated test code. What that means is that you check the GUI component for an expected result for example, if it’s not there (yet), put your test runner thread to sleep for a period of time, then check again, after some time, finally either finding the expected result or failing the test after a couple of retries whenever a configurable timeout applies.
All such active waiting looking for an asynchronous result will take time away from your overall test automation runtime, providing your less timely feedback. Personally, I like to stick with the XP practice of a 10-minute build, meaning compilation, unit test execution, and static code analysis provide me feedback for my code base within 10 minutes, or else I start to actively look for ways to make my builds faster. In my experience, there is a similar threshold when thinking about automated acceptance checks around the 90-120 minute marker where I do the same as well. Usually, tests operating through GUI elements are the first ones to speed up whenever I take a closer look into my test suites due to the above-mentioned reasons. If you can avoid the slow-down from the get-go, you’ll find yourself in a way more feedback-driven situation for longer. So avoid automating tests through the GUI as long as possible.
One last thing, in case you don’t know how to do that, I found the invaluable xUnit Test Patterns book a good start for that as well. You can read most of the patterns online as well.
Yeah right, but what if we really can’t change anything there and have to go through the GUI?
Of course, I realize that person that approached me probably asked the question for a reason and considered all I said in the above chapter. Having exhausted all other options, you may sometimes end up in a situation where there is currently no other option available to you rather than exercising your tests through the graphical user interface. To explain my rationale, maybe a picture says more than a thousand words:
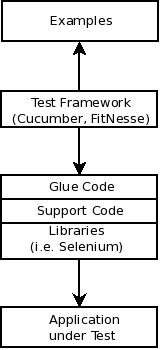
On the bottom, we find the application we want to automate tests for. No matter where your entry point to that application lies, your automated tests need to call functions in it. The box I called Libraries in the picture above can be thought of as a variety of different things that are available, and sometimes I split that box up into two or three different smaller boxes, usually the following: API drivers, UI drivers, and “non-official” drivers. What do I mean by those?
API drivers directly call official existing functions. For example, the GUI is hooked up through some calls to your application. Rather than going through the GUI, we go through those API calls, leading to less asynchronous wait time when running our tests, yet, leaving the minimal risk of whether the GUI is hooked up correctly to those API calls – maybe addressing that risk by just a set of exploratory test sessions before we ship.
By “non-official” drivers I’m referring to entry points to the system under test that just exist in our test environment, maybe. At my previous employer, we were testing tariffs and lifecycles in the mobile phone provider business. Some of these relied on running on a certain date in the month for different results, i.e. if that person made payments until the 21st of the month, the business rules had different outcomes. In order to yield reliable results when automating our tests, we had to make sure that some tests ran on the 19th of July 2079, and others on the 22nd of August 2078. There was an unofficial entry to the system to manipulate the system time, that helped us there. Of course, you don’t ship such a mechanism with your application for fraud protection reasons in production use. That’s why I call these entry points “non-official”.
Last but not least, we have GUI drivers. In the graphic above I listed Selenium for example for web applications. For most major GUI frameworks usually, you can find a library in your programming language of choice that enables you to simulate button clicks, enter data into fields, and so on. so, when I find myself pressed to go through the GUI, I try to seek such a library for the technology at hand.
That’s also where patterns like the page object pattern come into play. In essence, the page object pattern asks you to model for each GUI page the interaction elements in a separate class. I’m not totally sure whether I would consider page objects in the above graphic as support code or part of the various drivers you use, but that would be my thought process behind that.
Some final thoughts
Avoid testing through GUI. If you have to, find solutions to remote control your user interface, and prepare to get rid of those mechanisms once you are able to fix the design and architecture of your application under test. I found the more convoluted support code I needed for automating tests, I heard my test automation tell me that the elements closer to the business rules really should be in your application under test, yielding a more ubiquitous language.
If you wonder why I would go such a route, I am heavily influenced by Craig Larman’s pattern of offering “protected variations”, a pattern I learned early on. You want to avoid having to change lots of support code or even examples in case some elements get shifted around on the production user interface. Sometimes I consider the thoughts behind the “anti-corruption layer” in the DDD community have similar reasoning.
One thought on “Follow-up on: How do you automate tests through the GUI?”