Over the course of the Agile Testing Days in Berlin I realized why Exploratory Testing works. Personally I found a model from my past, which explains Exploratory Testing based on face-detection systems. After some initial feedback I decided to break it in three different posts: Learning, Scanning and the Differences. I will start with the part on Learning.
Introduction
The purpose of a face-detection system is to detect faces in images. There is a difference to face-recognition – that is recognizing that this particular face in the image is the face from a particular person, i.e. Markus Gärtner. Face-detection is the identification of possible faces, so we can evaluate these distinct portions of the picture to recognize which faces are there – which is the more costly operation. Similarly when testing exploratory we want to find out problematic areas quickly and then delve into them. When we file a bug into our tracking system or into our product backlog, we may leave it up to the pin-pointer to find out the problem behind the issue, if we don’t know the code – which is most often the case. Maybe we provide some additional informations about the software by doing some follow-up testing when a bug was found. More of this will be covered in the second write-up on this dealing with the scanning in Exploratory Testing and face-detection.
Learning
The approach for face-detection we used back in my university years is based on an offline-training approach. This means that you fed annotated data into some process, which then after several hours of computation gives you a working face detector. The data you will need consists of some face pictures and of several thousands of non-faces – ideally face-like structures in buildings or landscapes. Our face-detection approach back in 2003 was based on grey images. The detectors were constrained on 20 x 20 pixels – this was the size of the annotated face data. Even for most humans it was hard to detect a face on those grey-scale 20×20 pixel images. The images show really blurred faces. Here are five samples of a face which is scaled down to 20×20 pixels in a grey-scale image.

Our brain is capable of detecting a face in these samples, since it fills in the gaps with details based on our internal model on a face. Based on our past knowledge about the world, it makes the association to form a face and we can clearly recognize the five faces in the image above. If you open the image in an image editor and zoom it to 800 percent scale you might notice that it’s harder for our brain to do that extrapolation of (image) information which is not there. (Note that I already zoomed the image by a factor of three.)
This is comparable to the situation when we get a new version of some software. We have a blurred understanding of what the system shall be doing. We have a mental model, which fills some gaps there and extrapolates some informations based on our past knowledge. While playing with the system, we refine our model and when getting more informations about the system we get a finer resolution about that initially blurred picture of the software. By rejecting false positives – that are non-bugs in software and non-faces in face-detection training – our (bug- and face-) detectors get finer with each step we take.
Features
For the face-detector training there were several thousands features evaluated during the training phase. These features had 12 to 20 varying parameters. Here is a sample of a three block feature. x and y positions in the 20×20 pixels window, width and height (w, h) of the blocks and the distances between them (dx, dy, dx’) are the variables here.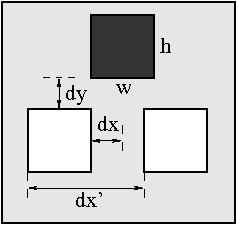
The training algorithm consisted of taking all valid combinations of these parameters, evaluating them on the face set and the non-face set and then picking that feature that could best reject non-faces, while still accepting most or all face samples. Note the non-linearity involved here. There were several hundreds of samples for faces in the training set, several millions of non-faces, and about 300,000 to 1,000,000 variations in the parameters for the features. All this together forms a multi-dimensional space, in which just a small subspace represents actual faces. The training algorithm would then identify this small subspace by keeping on iterating over the overall set of features again and again.
The analogy to Exploratory Testing here is that we have a small subspace of the working software within the multi-dimensional space which spans all possible software programs. Since we also have a very high dimensional space here, we are not able to finish the extensive search approach in our lifetime. This is impractical. Instead we need to find those sweet-spots where our (software-)features are. By getting in touch with our positive set of examples for working features (our customers, our acceptance-tests, our mental-model of the feature), we get to know what is feasible and what we need to reject. We are actually one of those non-face rejecting features while doing Exploratory Testing. We reject anything in the software, which does not provide value. We gather information necessary for this.
Variations
Thus far our approach to learning face-detection is quite trivial. In a refinement step later we played around with additional improvement to the learning algorithm. One thing that worked out pretty well was to skip some of the training features in first place. Instead of examining all possible features, the training got faster – from weeks to days – when we just used a subset – i.e. 2,000 features instead of 300,000. In order to compensate for the sub-optimized result we then used the parameters of the best non-face rejecting features there and varied them. If some minor variations of the top 10 features showed improvements, these were taken for another variation step, until these top 10 features stabilized. By then the best feature among these 10 was picked for the current training step.
In Exploratory Testing there is a similar situation. If we start to find a possible bug in the software, we start to dive into it in more detail with some small variations: inspecting how the software behaves if I use German umlauts in a text box, or clicking the menu options in a different order. We try to follow the path to the bugs that hide deep in the system when getting attracted. Just as the training algorithm tries to pick the right features using this heuristic, we are trying to pick the right tests to execute while we’re gathering information about the system. Note that this is a heuristic – and yes, heuristics are fallible. In the case of the face-detection algorithm there were plenty of different features available in the next training iteration, which are evaluated in the next learning step. Similarly Exploratory Testing may not find all bugs lurking in your system in the first place. Exploring the product iteratively though may yield a sufficiently tested application.
Conclusion
There are parallels between Exploratory Testing and the learning approach we used for face-detectors. In fact, the learning approach was based on observations about how humans learn. By learning about either the product or how faces look like, you keep on searching for either bugs or face-supporting features in your system. Just like the face-detection learning algorithm concentrated on the interesting features to save time in the training phase, Exploratory Testing may save time spent in testing.
But remember, Exploratory Testing does not guarantee to find all problems in your software. After all
When I want a guarantee, I buy a toaster.
Similarly sometimes we had detectors trained, which were not recognizing any face at all. By then we reflected over the course, why this did happen, and adapted our approach accordingly. Maybe we found out that we over-trained the detector, so that it was too fine to detect anything. (Can you name at least three possibilities how this can happen in testing?) By making this observation about the training, we were able to adapt our approach and refine it. Actually not the software system had learned something, but we ourselves – the observers.
One thought on “Exploratory Testing – Learning”