When it comes to functional test automation, most legacy application have to deal with the problem, that retro-fitting automated tests to an application that was not built with it from scratch, can be painful. In the long-run, teams may face one problem. The automated tests constrain further development on the production software. The tests are highly coupled to the software that they test. Let’s see how we can solve these problems with a clear architecture in the beginning of our automation journey.
The problem with test automation code on a functional level lies in the coupling. On one hand, we try to express in the examples the business requirements, and business rules. On the other hand, we need to connect to the system under test by any technical means possible.
In my experience the biggest problems occur when we couple both too deeply to each other. This is where programming concepts come into play that help us with low coupling towards the business rules we expressed in our examples, as well as towards the underlying system that we test.
This is a graphic from ATDD by example. It shows a solution to the problems that occur usually when retro-fitting acceptance test to your application. It’s based on agile friendly test automation tools.
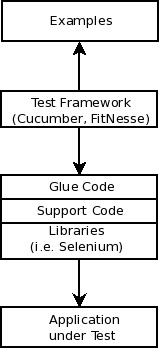
On the top we find the examples. These express our business rules. Ideally these have been discussed in a specification workshop together with SMEs, or business experts. Right below that, we find the test framework that connects the examples with the something that will connect to our application. On the bottom we find the application under test. This is the stuff that we are hooking up our tests against.
The interesting piece is the thing in the middle. I usually find myself separating between a thin layer of glue code, that is written for the framework in use. If you are using cucumber, this will be your step definitions, if you use FitNesse, this will be your fixture classes, if you use robot framework, this will be your test library, and keywords. Ideally the layer of glue code should be thin. In Domain Driven Design terms, the glue code layer provides an anti-corruption layer for the underlying support code. It translates the conventions that come from the examples and the test framework to code that you can re-use in general for testing your application.
For example, a couple of years ago, I worked with a test automation system on top of FitNesse. We had grown a large set of helper classes in our support code. The glue code layer then simply needed to provide framework-specific methods (in our case, this was Fixture code from the old FIT system), and call our little tiny helpers in the right way. A few months later, when we discovered SLiM, we were able to replace the glue code with the new conventions, and continue our test automation efforts. It would have been similar for us to replace the test framework completely with another framework. In fact, I remember a group of colleagues that integrated our support code into an android simulator to build a useful tool for the user acceptance tests directly in the plant of our customers.
The glue code provides protected variations when it comes to hooking up the framework with your application. It helps you to protect variations in how your application looks like today, to make it easy to change that without changing the examples at all. Also, the glue code layer provides protected variations when it comes to replacing your examples or your test framework. There is still a bunch of code that you can re-use.
In order to drive the application under test, you need to have driver classes. These are reflected in the Libraries box in the graphic. If you deal with a web front-end, then chances are, that Selenium is your driver. If you hook up your application behind the GUI, then you will probably grow own drivers. For examples, a few years back we used classes from the model in a model-view-presenter (MVP) GUI architecture. The model spoke to the underlying classes that would store data in a central database. By going behind the GUI we were able to make the tests more reliable. Last year, I was involved in a project involving hardware. We grew our own test libraries and test interfaces in that 20 MB Linux box, and were able to influence many of the indirect inputs to the system under test directly. On another product I worked with, we used helper classes that sent xml commands over a proprietary network connection to one of our C/C++-backends in order to trigger stuff there, execute something, or simply collect data to verify from those systems. We used it in combination with that EJB2 connections that were already in place in order to talk to the JBoss backend.
This layer of libraries provides also protected variations. Whenever something in the protocol towards your test application changes, you should just change one thing in your test code base. Otherwise you would be welcome to maintenance hell. (I have been there, don’t try.) This is virtually an anti-corruption layer for your application that lets you translate stuff from your application into terms suitable for the business rules expressed in the examples. When hooking up automated tests for an application that you don’t influence, you are very likely to need something like this. In other applications there might not need to translate your (application) business objects into a language the business – your customer – understands.
The support code in the middle, finally, should be modular enough so that you can re-use it as much as possible. That comes with a certain benefit: you should also unit test your test code when you think about larger functional test automation – especially if you are likely to re-use it. When I worked with a team of testers a few years back, we used that approach. We were able to reach 90%-95% code coverage in that code. It was really better tested than the application under test. We were way more flexible with the stuff that we had grown than our developers, since we refactored rigorously as well. I was never able to validate it, but I claim that such a modular structure with a high degree of automated tests also is better suited to introduce new colleagues.
Here’s an anecdote that I remember. There was a bug in our application that we shipped. The customer had raised it. I took a look, and talked to the programmer. We decided that we would work in parallel on the functional tests, and the implementation. I automated two to three cases that were derived from the bug report. They all failed in the old system. I needed to come up with some examples, and adapt some of our automation code. When I finished, I submitted my code to the code base. Then I went over to the programmer to check back. He was lost in the business code. At the end, we had walked over to my machine, implemented the correct behavior with the bug exposing tests running, and refactored a complicated three-times nested if-statement to something that even a programmer new to it could read and understand. At the end of the day, we submitted the code from my machine.
So, next time, you want to start with automated tests on a functional level, try to keep this graphic in mind. In the beginning you might not start with such an architecture. I don’t. What I do, is start from the examples, implement everything in glue code, and when I see structure evolving, I extract the support code that I need from it. Most of the times, I use TDD for that. Over time, you will realize stuff that changes often in your application. Try to apply the same pattern to the libraries that you grow, and keep your support code independent from it. Oh, and remember the Dependency Inversion Principle there. Over time, you will have a maintainable test automation suite, grown by use, and you are able to start delivering results from day one.
Good luck.
The beauty of test automation consists of simple solutions. I learned the hard way, that you constantly have to assess the status of your automated tests so it doesn’t become a huge monolith.
A rule of thumb I use is never add more than 1 extra layer in your framework, because will become unmanageable while glue code is being developed.
A bad practice I often see is that people developing automated tests, take on vertical slice of integration test and use it as sample for their entire future work. They often find themselves in the situation of duplicate code and bad design
I agree, Andrei. The problem usually is that people don’t recognize that they should rather push down some of the code from the first test into the test infrastructure thereby growing the test infrastructure over time.
Markus nicely explained your view points. This blog is full of information on automated tests. Thanks Markus hope to see next informative post.